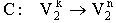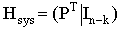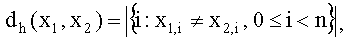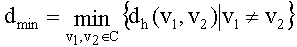При составлении этого раздела использовались работы [1; 2]. Рассмотрим двоичный линейный блоковый (n,k)-код С с порождающей матрицей G (размером k ? n) и проверочной матрицей Н (размером (n-k)? n).
2.1. Двоичный (n,k)-код С задается как отображение множества двоичных векторов длины k во множество двоичных векторов длины n:
2.2. Кодовое слово v  С (длины n) и информационное слово u (длины k) связаны соотношением: v=u?G. С (длины n) и информационное слово u (длины k) связаны соотношением: v=u?G.
2.3. Любое кодовое слово v С удовлетворяет условию vHT=0.
2.4. Произвольная порождающая матрица G линейного блокового (n,k)-кода может быть преобразована к систематической форме Gsys с помощью элементарных операций и перестановок столбцов матрицы. Матрица Gsys состоит из двух подматриц: k x k единичной матрицы, обозначаемой Ik и k x (n-k) проверочной подматрицы Р. Таким образом,
, а так как GHT=0, то отсюда следует, что систематическая форма проверочной матрицы имеет вид
2.5. Стандартная декодирующая таблица содержит 2n-k строк и 2k+1 столбцов. Процедура построения стандартной таблицы состоит в следующем.
А) Правые 2k столбцов заголовка таблицы заполним информационными словами, начиная с нулевого слова. Правые 2k столбцов первой строки заполняем кодовыми словами кода С (соответствующими информационным словам, указанным в заголовке) В первую ячейку первого столбца записываем нулевой синдром. Полагаем j=0.
В) Для j=j+1, находим шумовое слово ej V2 минимального веса Хемминга, не являющееся кодовым и не включенное в предыдущие строки таблицы. Соответствующий синдром sj=ejHT записываем в первый (крайний левый) столбец j-той строки. В оставшиеся 2k ячейки этой строки запишем суммы ej и кодовых слов uj. Отметим, что в случае кода с неравной защитой от ошибок, возможно совпадение значений синдрома для различных значений шумовых слов. При таком совпадении необходимо оставить только один вектор ej из векторов, имеющих одинаковые значения синдрома.
С) Повторяем шаг В процедуры пока j<2n-k, т.е. пока все вектора из V2 не окажутся включенными в таблицу.
Анализируя построенную таблицу нетрудно заметить, что все элементы одной и той же строки имеют один и тот же синдром. Элементы каждой строки представляют собой смежный класс кода С. А соответствующий вектор ej называется лидером смежного класса.
2.6. В двоичном пространстве V2 расстояние Хемминга определяется как число позиций, на которых два вектора не совпадают. Пусть x1=(x1,0, x1,1, …, x1,n-1) и x2=(x2,0, x2,1, …, x2,n-1) два вектора в V2. Тогда расстояние Хемминга между векторами x1 и x2, обозначаемое как dh(x1,x2), равно
где через |A| обозначено число элементов в А.
2.7. Весом Хемминга слова w из пространства V2 называют число wth(w) его ненулевых позиций, иными словами wth(w) это расстояние Хемминга между нулевым словом и словом w.
2.8. Для заданного кода С минимальное Хеммингово расстояние dmin определяется как минимум Хеммингова расстояния по всем возможным парам различных кодовых слов
Согласно этой формуле, для определения минимального кодового расстояния произвольного блокового кода С необходимо вычислить 2k(2k-1) расстояний между различными парами кодовых слов. Часто эта задача практически невыполнима. Одним из важных преимуществ линейных блоковых кодов является то, что для вычисления dmin достаточно знать только Хемминговы веса 2k-1 ненулевых слов.
Двоичный линейный (n,k)-код С с минимальным расстоянием Хемминга dmin>=2t+1 может обнаружить dmin-1 ошибок и исправить t ошибок. |