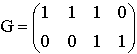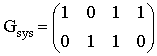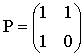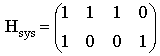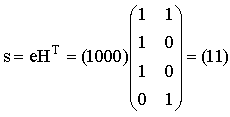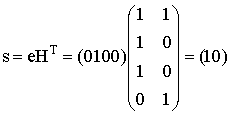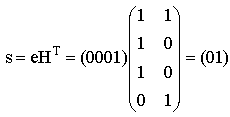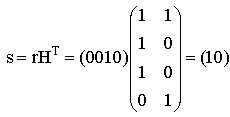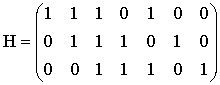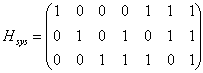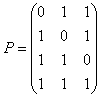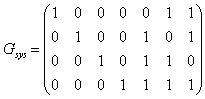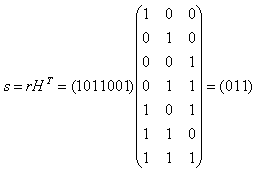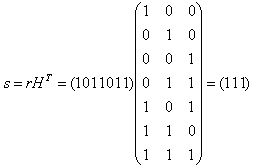|
Пример 1. Выполнение типового контрольного задания (см. раздел 1) для заданной генерирующей матрицы G.
А) Известно, что генерирующая матрица имеет размер (k x n), где k – число строк матрицы, а n – число столбцов. Скорость кода вычисляется как отношение значения k к значению n. Следовательно, длина n кода равна 4, размерность кода k равна 2, а скорость кода равна 2/4=1/2.
В) Для вычисления количества кодовых слов воспользуемся тем фактом, что двоичный (n,k)-код С любому двоичному вектору длины k ставит в соответствие одно кодовое слово длины n. Следовательно количество кодовых слов кода С совпадает с числом всех возможных двоичных векторов длины k; число таких векторов определяется как 2k. В рассматриваемом примере число кодовых слов равно 22=4.
C) Преобразуем матрицу G в систематический вид
. Для чего переставим второй и четвертый столбцы:
таким образом, проверочная подматрица равна
Отметим, что в данном случае выполняется соотношение Р=РТ. Коды, у которых выполняется такое соотношение, называются самодуальными. Согласно формуле 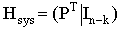 запишем проверочную матрицу
запишем проверочную матрицу
D) Информационными словами u являются все возможные двоичные слова длины k=2. Кодовые слова v вычислим, используя формулу v=u?G. Отметим, что в зависимости от того, в систематическом или несистематическом виде использовать порождающую матрицу, одному и тому же информационному слово могут соответствовать различные кодовые слова. Несмотря на это полученные коды будут изоморфными.
|
Информа-ционные слова |
Кодовые слова в систематической форме |
Кодовые слова в несистематической форме |
|
(00) |
(0000) |
(0000) |
|
(01) |
(0110) |
(0011) |
|
(10) |
(1011) |
(1110) |
|
(11) |
(1101) |
(1101) |
E) Организуем таблицу размером 5 столбцов и 4 строки. Выполним шаг А процедуры построения декодирующая таблицы. А именно, запишем в заголовок таблицы все информационные слова, а в первую строку соответствующие им кодовые слова. Для выполнения этих действий воспользуемся результатами, полученными при выполнении задания D.
Для j=1 находим произвольное слово e1IV2 минимального веса Хемминга, не являющееся кодовым и не включенное в предыдущие строки таблицы. Пусть e1=1000, вычисляем синдром этого вектора по формуле s=eHT
Запишем полученный синдром s1=11 в первый столбец второй строки. В остальных ячейках этой строки запишем суммы кодовых слов из первой строки и вектора ошибок e1=1000.
Увеличиваем j на единицу. Для j=2 находим произвольное слово e2IV2 минимального веса Хемминга, не являющееся кодовым и не включенное в предыдущие строки таблицы. Пусть e2=0100, вычисляем синдром этого вектора
Запишем полученный синдром s2=10 в первый столбец третьей строки. В остальных ячейках этой строки запишем суммы кодовых слов из первой строки и вектора ошибок e2=0100.
Увеличиваем j на единицу. Для j=3 находим произвольное слово e3IV2 минимального веса Хемминга, не являющееся кодовым и не включенное в предыдущие строки таблицы. Пусть e3=0001, вычисляем синдром этого вектора
Запишем полученный синдром s3=01 в первый столбец четвертой строки. В остальных ячейках этой строки запишем суммы кодовых слов из первой строки и вектора ошибок e3=0001.
|
s |
00 |
01 |
10 |
11 |
|
|
00 |
0000 |
0110 |
1011 |
1101 |
Строка 1 |
|
11 |
1000 |
1110 |
0011 |
0101 |
Строка 2 |
|
10 |
0100 |
0010 |
1011 |
1001 |
Строка 3 |
|
01 |
0001 |
0111 |
1010 |
1100 |
Строка 4 |
Увеличиваем j и заканчиваем построение таблицы, так как для j=4 не выполняется условие j<2n-k.
У рассматриваемого кода 4 смежных класса, лидерами которых являются: e0=0000, e1=1000, e2=0100, e3=0001.
При построении таблицы в качестве вектора ошибок не был выбран вектор e=0010. Причина этого заключается в том, что синдром этого вектора совпадает с синдромом вектора e2=0100, что в свою очередь происходит из-за того, что данный код является кодом с неравной защитой от ошибок, то есть число исправляемых ошибок зависит от местоположения ошибок.
F) Пусть в канал было передано кодовое слово с=0110, а из канала принято слово r=0010. Рассчитаем синдром для принятого вектора и декодируем его, используя стандартную таблицу.
По декодирующей таблице находим, что синдром s=10 находится в третьей строке. В этой же строке отыскиваем вектор r=0010. В первой строке этого же столбца находится переданное кодовое слово с=0110. Одиночная ошибка в слове исправлена. Этот факт выглядит странно, так как минимальное расстояние рассматриваемого кода равно 2, а, следовательно, исправление однократных ошибок не гарантируется. Объяснение этого факта заключается в том, что, как уже отмечалось, данный код является кодом с неравной защитой от ошибок.
G) Для вычисления способностей кода по исправлению и обнаружению ошибок вычислим минимальное расстояние Хемминга для этого кода, как минимум Хемминговых весов ненулевых кодовых слов кода С (см. раздел 2.7). Веса Хемминга кодовых слов: wth(0110)=2, wth(1011)=3, wth(1101)=2. Минимальное расстояние Хемминга: dmin=min{2, 3, 2}=2. Используя формулу из раздела 2.8, вычисляем, что рассматриваемый код гарантировано обнаруживает 1 ошибку, а исправляет 0 ошибок.
Пример 2. Выполнение типового контрольного задания (см. раздел 1) для заданной проверочной матрицы H.
A. Проверочная матрица Н имеет размер (n-k)? n. Следовательно, длина кода n=7, размерность кода k=n-(n-k)=7-3=4, скорость кода равна 4/7.
B. Число кодовых слов определяется как 2k=24=16.
C. Приведем матрицу H к систематическому виду. Переставим местами столбцы 2 и 6, 3 и 7.
Правые четыре столбца матрицы Hsys представляют собой транспонированную проверочную подматрицу Р. Выпишем матрицу Р:
Согласно формуле 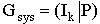 запишем порождающую матрицу в систематическом виде запишем порождающую матрицу в систематическом виде
D. Информационными словами u являются все возможные двоичные слова длины k=4. Кодовые слова v вычислим, используя формулу v=u?G и используя матрицу Gsys.
|
u i |
vi |
u i |
vi |
u i |
vi |
|
(0000) |
(0000000) |
(0110) |
(0110011) |
(1100) |
(1100110) |
|
(0001) |
(0001111) |
(0111) |
(0111100) |
(1101) |
(1101001) |
|
(0010) |
(0010110) |
(1000) |
(1000011) |
(1110) |
(1110000) |
|
(0011) |
(0011001) |
(1001) |
(1001100) |
(1111) |
(1111111) |
|
(0100) |
(0100101) |
(1010) |
(1010101) |
|
|
|
(0101) |
(0101010) |
(1011) |
(1011010) |
|
|
E. Стандартная декодирующая таблица этого кода должна содержать 2n?k=27?4=8 строк и 2k+1=24+1=17 столбцов. Для удобства разделим эту таблицу по ширине на две части (табл. 1), которые заполним согласно процедуре построения из раздела 2.4.
У рассматриваемого кода 8 смежных классов, лидерами которых являются: e0=0000000, e1=0000001, e2=0000010, e3=0000100, e4=0001000, e5=0010000, e6=0100000, e7=1000000.
F) Пусть в канал было передано кодовое слово с=0011001 (соответствующее информационному слову u=0011), а из канала принято слово r=1011001 (содержащее один ошибочный символ). Синдромом для r является вектор s:
В табл. 1 синдрому s=(011) соответствует строка 5, двигаясь по этой строке, отыскиваем полученный из канала вектор r=1011001 и находим соответствующее этому вектору информационное слово u=0011. Вывод: декодирование успешно.
Пусть теперь в канал было передано кодовое слово с=0011001 (соответствующее информационному слову u=0011), а из канала принято слово r=1011011 (два ошибочных символа). Вычислим синдром s:
В табл. 1 синдрому s=(111) соответствует строка 2, двигаясь по этой строке, отыскиваем полученный из канала вектор r=1011011 и находим соответствующее этому вектору кодовое слово u=1011. Вывод: декодирование неудачно.
G) Минимальное расстояние Хемминга этого кода найдем как минимум Хемминговых весов dmin=min{ wth(0001111)=4, wth(0010110)=3, wth(0011001)=3, wth(0100101)=3, wth(0101010)=3, wth(0110011)=4, wth(0111100)=4, wth(1000011)=3, wth(1001100)=3, wth(1010101)=4, wth(1011010)=4, wth(1100110)=4, wth(1101001)=4, wth(1110000)=3, wth(1111111)=8}=3. Следовательно, рассматриваемый код гарантировано обнаруживает две, а исправляет 1 ошибку.
Таблица 1. Часть 1
|
s |
(0000) |
(0001) |
(0010) |
(0011) |
(0100) |
(0101) |
(0110) |
(0111) |
|
|
(000) |
(0000000) |
(0001111) |
(0010110) |
(0011001) |
(0100101) |
(0101010) |
(0110011) |
(0111100) |
Строка 1 |
|
(111) |
(0000001) |
(0001110) |
(0010111) |
(0011000) |
(0100100) |
(0101011) |
(0110010) |
(0111101) |
Строка 2 |
|
(110) |
(0000010) |
(0001101) |
(0010100) |
(0011011) |
(0100111) |
(0101000) |
(0110001) |
(0111110) |
Строка 3 |
|
(101) |
(0000100) |
(0001011) |
(0010010) |
(0011101) |
(0100001) |
(0101110) |
(0110111) |
(0111000) |
Строка 4 |
|
(011) |
(0001000) |
(0000111) |
(0011110) |
(0010001) |
(0101101) |
(0100010) |
(0111011) |
(0110100) |
Строка 5 |
|
(001) |
(0010000) |
(0011111) |
(0000110) |
(0001001) |
(0110101) |
(0111010) |
(0100011) |
(0101100) |
Строка 6 |
|
(010) |
(0100000) |
(0101111) |
(0110110) |
(0111001) |
(0000101) |
(0001010) |
(0010011) |
(0011100) |
Строка 7 |
|
(100) |
(1000000) |
(1001111) |
(1010110) |
(1011001) |
(1100101) |
(1101010) |
(1110011) |
(1111100) |
Строка 8 |
Таблица 1. Часть 2
|
s |
(1000) |
(1001) |
(1010) |
(1011) |
(1100) |
(1101) |
(1110) |
(1111) |
|
|
(000) |
(1000011) |
(1001100) |
(1010101) |
(1011010) |
(1100110) |
(1101001) |
(1110000) |
(1111111) |
Строка 1 |
|
(111) |
(1000010) |
(1001101) |
(1010100) |
(1011011) |
(1100111) |
(1101000) |
(1110001) |
(1111110) |
Строка 2 |
|
(110) |
(1000001) |
(1001110) |
(1010111) |
(1011000) |
(1100100) |
(1101011) |
(1110010) |
(1111101) |
Строка 3 |
|
(101) |
(1000111) |
(1001000) |
(1010001) |
(1011110) |
(1100010) |
(1101101) |
(1110100) |
(1111011) |
Строка 4 |
|
(011) |
(1001011) |
(1000100) |
(1011101) |
(1010010) |
(1101110) |
(1100001) |
(1111000) |
(1110111) |
Строка 5 |
|
(001) |
(1010011) |
(1011100) |
(1000101) |
(1001010) |
(1110110) |
(1111001) |
(1100000) |
(1101111) |
Строка 6 |
|
(010) |
(1100011) |
(1101100) |
(1110101) |
(1111010) |
(1000110) |
(1001001) |
(1010000) |
(1011111) |
Строка 7 |
|
(100) |
(0000011) |
(0001100) |
(0010101) |
(0011010) |
(0100110) |
(0101001) |
(0110000) |
(0111111) |
Строка 8 |
|