3. Идеи построения алгоритма сжатия Лемпеля-Зива
1. Каждая очередная
закодированная последовательность символов добавляется к раннее
закодированным символам таким образом, что вместе с ними она образует
разложение всей принятой и переданной информации на несовпадающие
между собой фразы. Такое разложение хранится в памяти и используется
в дальнейшем в качестве словаря.
2. Кодирование осуществляется
при помощи указателей на фразы из уже сформированного словаря фраз.
Кодирование является динамической процедурой, ориентированной на блоки.
Сам процесс кодирования может быть дополнен скользящими окнами,
содержащими текущий словарь фраз, и Look-ahead буфером.
Пример. Используя Zip–модификацию алгоритма
Лемпеля-Зива, закодировать последовательность
На начальном
этапе работы алгоритма динамически формируемый словарь пуст. Пока
словарь пуст, будем просматривать кодируемую фразу посимвольно и
кодировать отдельные символы, по мере заполнения словаря будем
пытаться кодировать в один пакет данных несколько подряд идущих
символов.
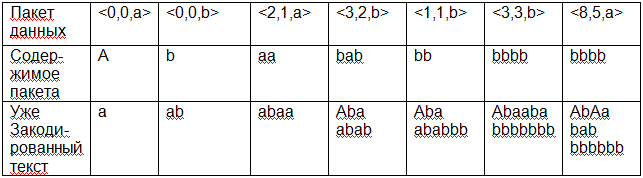
Сформируем первый пакет данных и добавим его в словарь.
Первый символ кодируемой последовательности (*) – «а» запишем по
первому адресу. Пакет данных будет иметь вид: <0,a>. При формировании
текущего пакета данных не используется ссылка на содержимое других
позиций словаря, поэтому первый элемент пакета данных равен нулю,
значение следующего знака данных равно «а», – символу, который
необходимо записать в словарь.
Адрес: 1
Пакет данных: <0,a>
Содержимое: а.
Второй символ кодируемой последовательности
(*) – «в» запишем по второму адресу. Пакет данных будет иметь вид:
<0,в>. При формировании этого пакета данных также не используется
ссылка на содержимое других позиций словаря, поэтому первый элемент
пакета данных равен нулю, а значение следующего знака данных равно
«в», – символу, который необходимо записать в словарь.
Адрес: 2
Пакет данных: <0,в>
Содержимое: в.
Просматриваем далее входную последовательность
abaababbbbbbbabbbba. Будем отмечать в ней подчеркиванием уже
закодированные символы. Следующий из незакодированных символов –
«а» уже встречался в словаре, поэтому теперь в один пакет запишем
объединение этого символа со следующим
Адрес: 3
Пакет данных: <1,а>
Содержимое: аа.
Запись <1,а> в пакете данных означает, что
необходимо взять символ(ы) записанные по адресу 1 и добавить к ним
символ «а». Далее будем аналогичным образом продолжать процесс
кодирования, каждый раз просматривая динамически формируемый словарь
справа налево, т.е. с последней записи к первой. Оформим процесс
кодирования в таблицу.
Пример.
Используя LZW–модификацию алгоритма Лемпеля-Зива, закодировать
последовательность
-очень эффективно кодируются
повторяющиеся символы и часто появляющиеся цепочки символов;
-редко повторяющиеся символы и последовательности символов
с течением времени удаляются из словаря фраз;
-кодирование начальных фраз затрачивается
относительно большое количество бит;
-методы теории информации позволяют доказать, что кодирование методом
Лемпеля-Зива асимптотически оптимально. Это означает, что для очень
длинного текста избыточность исчезает, то есть среднее число бит,
необходимое для кодирования текста стремиться к энтропии текста;
-практическая степень сжатия для длинных текстов составляет 50-60%.