• Axiom of reflexivity: (B
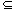
A) ═> (A→ B);
• Axiom of augmentation: (A → B) ═> (AС→ BС);
• Axiom of transitivity: (A → B) ^ (B→ C)═> (A →C);
• Self-determination: A A;
• Decomposition: (A → BС) ═> (A→ B) (A → С);
• Union: (A → B)^ (A → С)═> (A → BС);
• Composition: (A→ B)^ (C→ D)═> (AC → BD);
• Darwen’s GUT: (A → B)^ (С → D)═> (А
(С – B)→ BD ).
•
Example 1: Darwen’s «General Unification Theorem» proof
This proof is answer on exercise number 11.5 from Date’s book [1].
Given: (A → B) and (С→ D).
Proof:
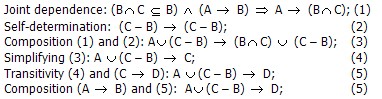
This completes the proof.
3. Closure of a set of FDs and closure of a set of attributes
The set of all FDs that are implied by a given set S of FDs is called the closure of S and written S+.
Example 2: Closure of FDs
Suppose we are given a relvar (relational variable) R with attributes A, B, C, D, E, F and the FDs: A→ BC, B → E, CD → EF. Show that the FD AD→ F holds for R and is thus a member of the closure of the given set:
1. A→ BC (given)
2. A → C (decomposition for 1)
3. AD → CD (augmentation for 2)
4. CD→ EF (given)
5. AD→ EF (transitivity for 3 and 4)
6. AD→ F (decomposition for 5)
The completion of a finite set of attributes X under a finite set of FDs S, written as X + , is the smallest superset of X such that:
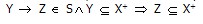 Example 3:
Example 3: Computing the closure of the set attributes.
Suppose we are given a relvar R with attributes A, B, C, D, E, F, and FDs: S = {A → BC, E → CF, B → E, CD → EF}. Now compute the closure {A,B}+ of set attributes {A,B} under S.
1. Initialize result set to {A,B} (hereinafter in this section referred to as «CLOSURE»).
2. Look at the first FD: we add attribute C (and B) to CLOSURE because the left side is indeed a subset of CLOSURE and CLOSURE is now the set {A, B, C}.
3. The left side of second FD is not a subset of the CLOSURE.
4. The left side of third FD is indeed a subset of CLOSURE and CLOSURE is now the set {A, B, C, E}.
5. The left side of fourth FD is not a subset of the CLOSURE and CLOSURE remains unchanged.
6. Now we go round the inner loop four times again. On the first FD, the result does not change; on the second, it expands to {A, B, C, E, F}; on the third and fourth, it does not change.
7. Change stop for CLOSURE. By this is meant that process terminate and also that {A, B}+ = {A, B, C, E, F}.
Given a set S of FDs, we can easily tell whether a specific FD X → Y follows from S, as FD will follow if and only if Y is a subset of the closure X+ of X under S. In other words. we have a simple way of determining whether a given FD X → Y is in the closure S+ of S, without actually having to compute the closure S+.
4. Algorithm to derive candidate keys from functional dependencies
INPUT: a set S of FDs that contain only subsets of a header H
OUTPUT: the set C of superkeys that hold as candidate keys in
all relation universes over H in which all FDs in S hold
begin





